2026年4月8日
3152 Lecture 5
Clustering
Lecture Slide: FIT3152 Lecture 05.pdf
Previous: 3152 Lecture 4 - Regression Modelling Next: 3152 Lecture 6 - Decision Tree
Clustering
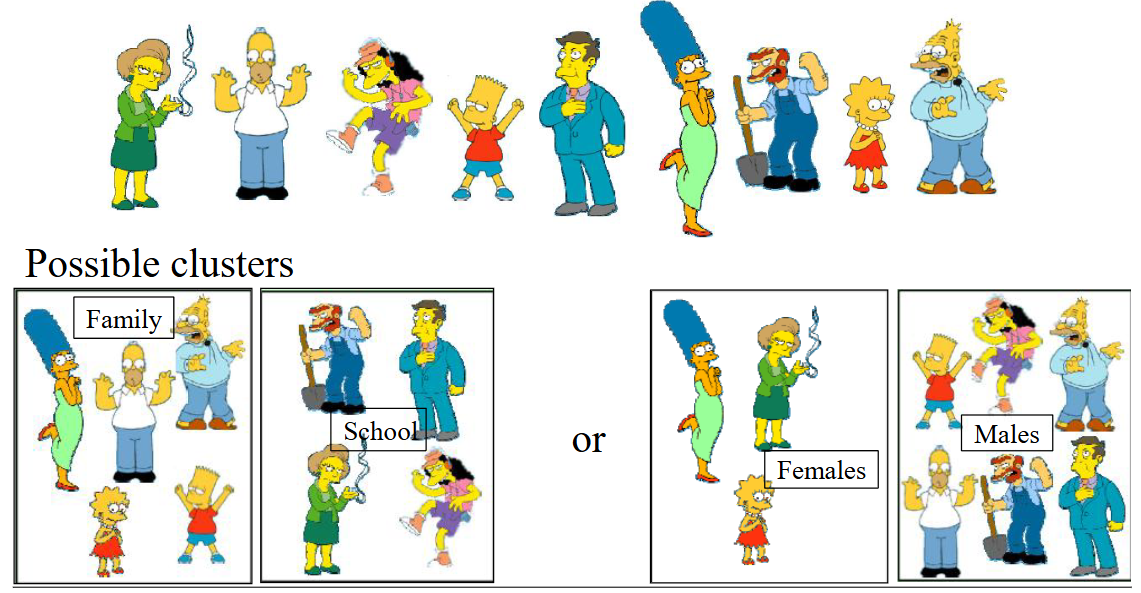
Clustering is unsupervised learning method. The purpose cluster the unlabelled data. Which means it separate the data in to multiple group based on the observed pattern of the data.
Clustering can also be used in real world like group houses based on similar features, clustering the email by content etc.
K-Means Clustering
In K-Means Clustering, each cluster is associated with a centroid (centre point). The rest of points will be assigned to nearest centroid to be come a cluster. Number of cluster must be specified in order to set the number of centroid.
The K-Means Clustering will do the below process:
- Randomly select centroids
- Assigned each point to nearest centroid to form clusters
- Among each cluster, find the new centroid at the centre of cluster
- Repeat the step of Sign and recompute centroid until centroids doesn’t change or doesn’t change much
Euclidean distance
By using the Euclidean distance we can know how far between two points. It basically use Pythagoras Theorem.
This can also represent as , where: Basically, the purpose of K-Means clustering is to minimize the total squared distance of each point to its cluster centroid.
[!NOTE] K-Median K-median will use the total absolute distance rather than squared distance. Squared distance is more aware of outliers, and absolute distance is more robust but harder to find centroid because centroid is likely to have same total absolute distance.
For more information, see Extra Note - K-medians
This could be written as: Where:
Evaluate
To evaluate the K-Means clustering, we simply compare the total squared distance above, this is also known as Sum of Squared Error (SSE). By changing the , the SSE changes, we will find the that has smallest SSE.
However, the easiest way to reduce SSE is to increase , because more clusters usually make points closer to their own centroid.
So SSE should not be used alone.
[!NOTE] SSE This is also mentioned in 2086 Lecture 3 - Estimation and Maximum Likelihood#Sum of the squared error. In FIT2086, we use SSE to minimise the distance between sample values and one estimated mean .
In K-means, this idea is extended to K means, where each centroid minimises the within-cluster SSE.
Silhouette
Silhouette is another method to evaluate clustering.
It measures how well each data point sits within its cluster.
For each point :
The silhouette score is:
Ideally, should be small and should be large.
This means the point is close to points in its own cluster, and far from points in other clusters.
The value of is between -1 and 1.
- close to 1 means the point is well clustered.
- close to 0 means the point is near the boundary between clusters.
- close to -1 means the point may be assigned to the wrong cluster.
Average silhouette can be used to compare different values of .
The with larger average silhouette score is usually better.
Accuracy
Accuracy can be used when we have actual labels to compare with the fitted clusters.
If the clustering result matches 125 points out of 150:
But clustering is unsupervised learning, so normally there are no true labels.
If there are no actual labels, we should use methods like SSE, Silhouette, or elbow method instead.
Fuzzy Clustering
Fuzzy Clustering is a clustering approach that is less strict than normal clustering like K-Means. The point in K-Means must be assigned to one and only one cluster.
This may lead to inaccuracy if clusters are close and mixed with each other, where the edge between clusters is unclear.
Fuzzy Clustering uses soft assignment instead of hard assignment. It allows a point to not only belong to one cluster. Fuzzy Clustering will assign a point with membership values. For example:
Point A:
Cluster 1 membership = 0.7
Cluster 2 membership = 0.2
Cluster 3 membership = 0.1The range of membership is:
Where means the membership value of point in cluster .
The sum of all membership values for the same point is 1.
Where is the number of clusters.
Fuzzy membership can be interpreted as probabilities for belonging in different clusters.
Fuzzy K-Means
Fuzzy K-Means is a fuzzy version of K-Means. It introduces the membership value into the normal K-Means objective function. For normal K-Means, each point only contributes to one cluster. For Fuzzy K-Means, each point can contribute to multiple clusters based on its membership values.
The objective function is:
Where:
The fuzzifier controls how fuzzy the membership distribution is. In the most of the time, . If , the result becomes closer to crisp K-Means.
Hierarchical Clustering
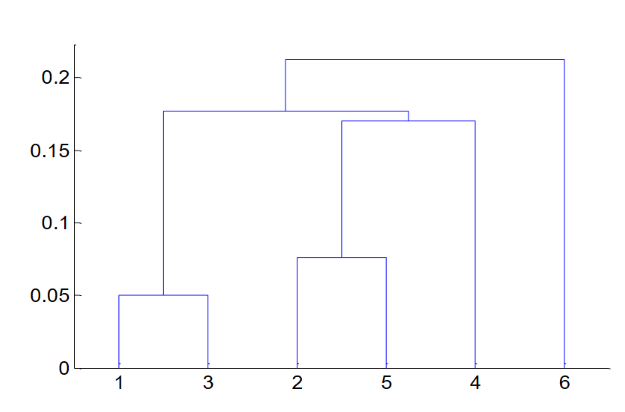
Hierarchical Cluster does not need to set the cluster number. It will generate a hierarchical tree structure called dendrogram (树状图), by cutting the dendrogram at different level, it forms clusters with different size.
There are two main types of hierarchical clustering:
- Agglomerative
- Divisive
Agglomerative is the more common method. It starts with each data point as one cluster, then repeatedly merge the closest clusters.
Divisive is the opposite. It starts with all data points in one cluster, then repeatedly split the cluster into smaller clusters.
The branch height in dendrogram represents the distance between clusters.
If two clusters are merged at lower height, they are more similar.
If two clusters are merged at higher height, they are less similar.
Different rules can be used to decide the distance between clusters, such as MIN, MAX, Group Average, and Distance Between Centroids. Different rules may produce different dendrograms and different clustering results.