2026年4月15日
3152 Lecture 6
Decision Tree
Lecture Slide: FIT3152 Lecture 06.pdf
Previous: 3152 Lecture 5 - Clustering
Next: 3152 Lecture 7 - Naive Bayes Classification and Evaluate performance
[!NOTE] Other Unit In FIT2086, we also mentioned this at 2086 Lecture 9 - Trees and Nearest Neighbour Methods#Decision Trees But this is the extended one.
Entropy
Entropy (信息熵) measure the chaos in a system (in Thermodynamics). In Information Theory, it represent the uncertainty in a random variable. In the other word, it measures the information included in an event.
The higher the entropy, the more information is included. A real world example, Chinese has higher entropy comparing to English per character.
In Decision Tree, entropy is used to measure how mixed the target classes are. If all examples belong to the same class, entropy is 0. If the classes are evenly mixed, entropy is high.
The entropy can be calculated as below for event:
For example, if class is Yes / No:
Gain
Gain measures that how much the entropy will decrease after split comparing to before
In natural language, .
The higher the Gain is, the more effective the split is, because more uncertainty or impurity is removed after the split. We want to minimise the entropy left after each split, so the tree can separate the classes more efficiently with fewer splits.
Decision Tree
Decision Tree is a classification model that splits the dataset based on predictor variables. Each internal node represents a test on one predictor, each branch represents one possible value of that predictor, and each leaf node represents the predicted class.
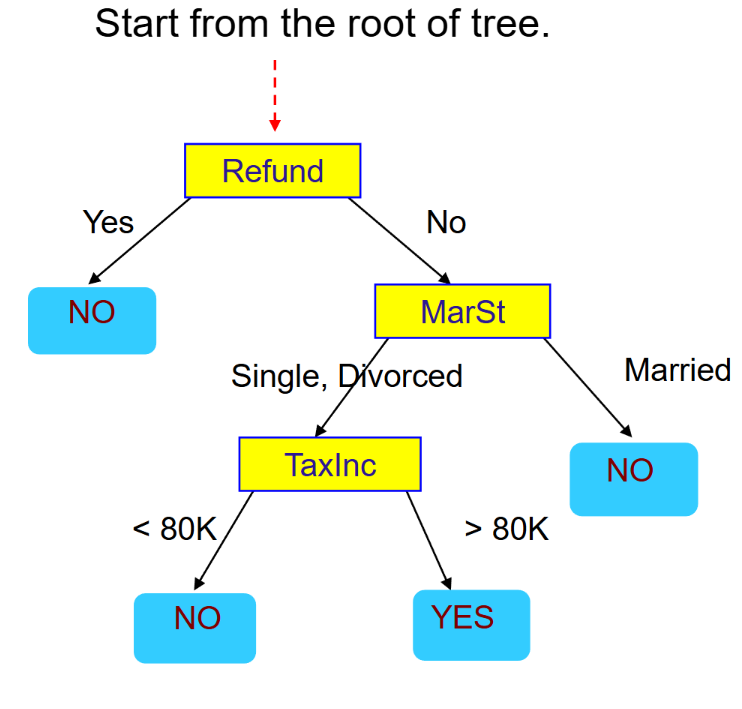
ID3
ID3 is a specific decision tree algorithm. It uses entropy and information gain to decide which attribute should be used for splitting.
The basic idea is that a good split should make the child groups more pure, it will increase the homogeneity (同质性). In other words, after splitting, each group should contain examples that mostly belong to the same class, so the entropy after split should be lower.
ID3 is a greedy algorithm, once the split attribute is been made, it can not be change in the rest of the tree. For each step ID3 only focus on the maximum gain in current step. By choosing the local maximum gain doesn’t mean it is the global best option.
The process of building a tree with ID3:
- Calculate the entropy of the current dataset.
- For each predictor attribute, split the dataset by its possible values.
- Calculate the weighted average entropy after the split.
- Calculate the information gain for each attribute.
- Choose the attribute with the highest gain as the split node.
- Repeat the same process for each branch that is still impure.
The root node is the first attribute chosen by ID3. It should be the attribute with the highest information gain, because it removes the most uncertainty from the original dataset.
After choosing the root, each value of that attribute becomes a branch. If all examples in a branch belong to the same class, then this branch becomes a leaf node. If the branch still contains mixed classes, then ID3 will calculate gain again using the remaining attributes and continue splitting.
The splitting stops when the data in a node is pure, which means entropy is 0, or when there are no useful attributes left to split.
So the overall goal of ID3 is to choose the attribute that gives the purest class breakdown at each step.